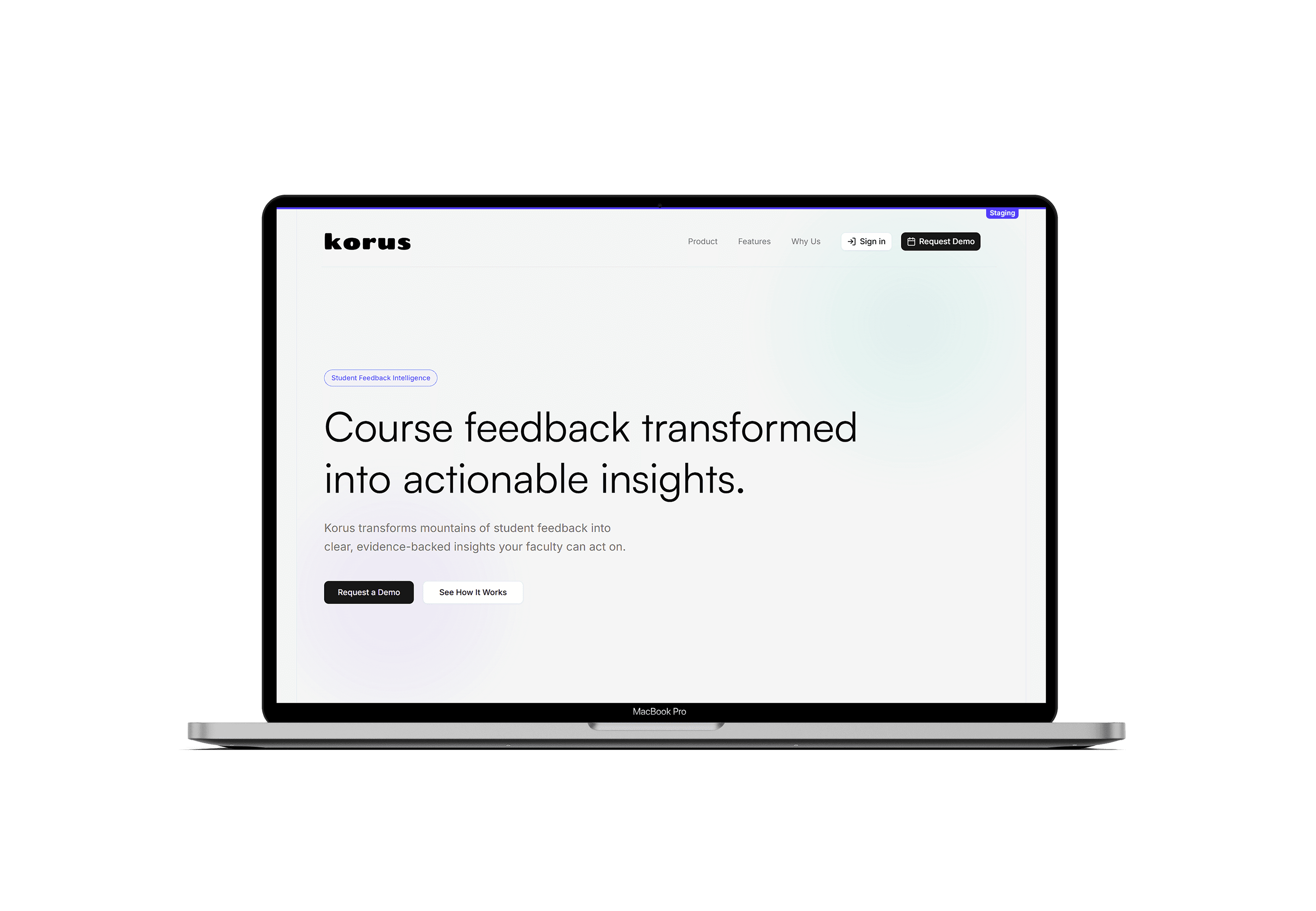
Course feedback transformed into actionable insights.
What is Korus?
Universities collect more student feedback than ever. At the University of Utah alone, 28,000 students submit course evaluations for 6,000+ faculty every semester. That's over 100 million comments since 1998. But thousands of open-ended comments sit unread, insights go unshared, and the gap between feedback and action keeps growing.
Korus surfaces meaningful insights from those voices in one compliant, educator-designed platform.
I built Korus from the ground up to close the loop between what students say and what leaders decide to change, transforming mountains of qualitative feedback into clear, evidence-backed insights faculty can act on.
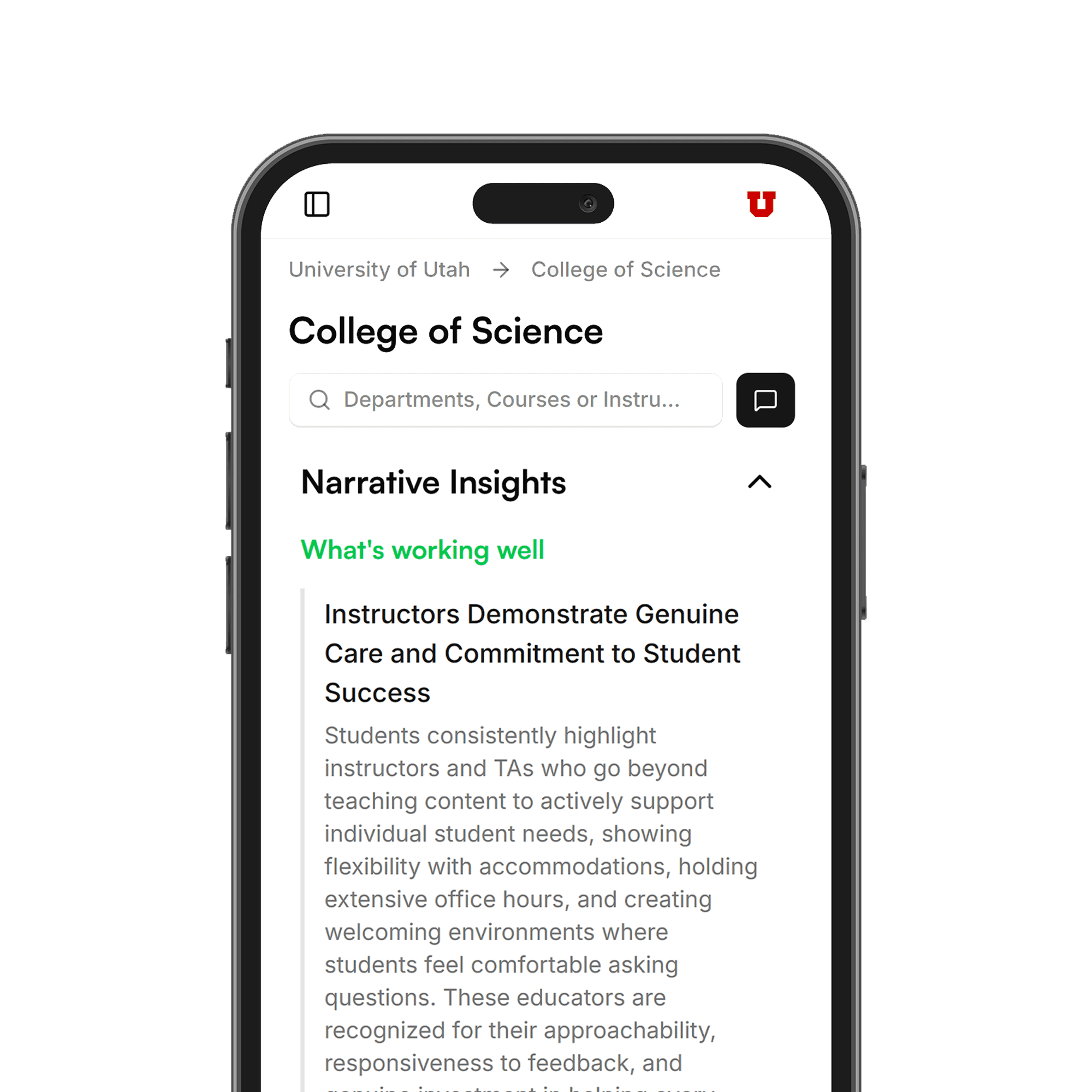
A micro-to-macro view of feedback and performance.
Korus supports multi-scope analysis: institutional health, college performance, department patterns, aggregated course feedback, and individual faculty effectiveness. Leaders see patterns at the right level, from high-level trends to actionable course-level insights.
Six capabilities work in concert: topic discovery (automatic theme surfacing, no tagging), sentiment trends (track shifts across semesters and departments), narrative insights (plain-language summaries for leaders), clean reports (shareable in seconds), cross-course comparisons (see what separates best-rated courses), and enterprise distribution (SSO-powered access).
Data shown is for representation in portfolio only, not real data.
ML pipeline: topic discovery and sentiment analysis.
The topic pipeline is a GPU-enabled ML workflow that transforms raw student comments into structured topics and sentiment insights. It runs as a batch process, ingesting from MongoDB and writing enriched results back for the Korus dashboard to consume.
The algorithm stack: Sentence-BERT for embeddings, UMAP for dimensionality reduction, HDBSCAN for clustering, GPT-4o-mini for topic labeling, and RoBERTa-based transformers for sentiment. The pipeline runs per unit (college, department) and once for global scope, supporting Korus's micro-to-macro view from institutional trends down to course-level insights.
Pulls open-ended comments from the database and filters them so topics can be analyzed at different levels, from a single department to the whole institution.
Splits each comment into sentences using NLTK/spaCy. Sentence-level granularity supports multiple topics and mixed sentiment per comment. Short or trivial fragments are filtered out.
Sentence-BERT encodes each sentence into a dense vector. Runs on GPU for speed.
UMAP reduces the vectors to fewer dimensions while preserving structure, making clustering more effective.
HDBSCAN finds dense regions without a fixed number of clusters and handles sentences that don't fit any topic.
LLM step (GPT-4o-mini) generates short 2–5 word titles for each cluster from keywords and example sentences. Makes topics interpretable in the UI.
Assigns each sentence to a topic with a confidence score. Outliers from HDBSCAN get soft assignments to the nearest cluster when above a threshold.
Transformer-based model (e.g., RoBERTa) classifies each sentence as positive, negative, or neutral. Runs on GPU. Results join with topic assignments so each topic has a sentiment distribution.
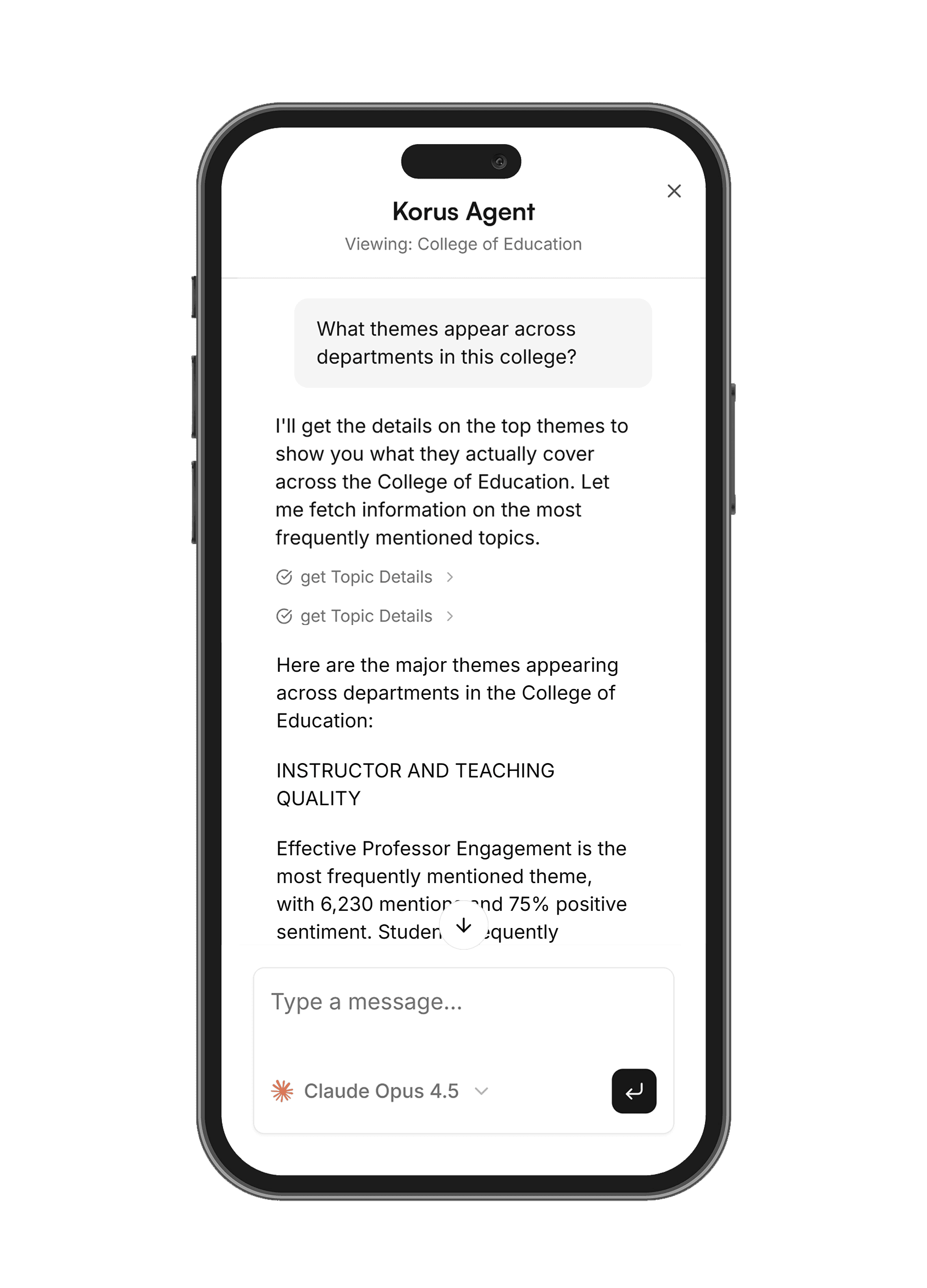
The AI agent works in tandem with discovered topics.
The AI agent uses the discovered themes as structured context. It delivers narrative insights, plain-language summaries for leaders, and answers questions in the context of what students are actually saying.
Topics provide the structure; the agent adds interpretation and synthesis. Leaders get both the raw topic data and an intelligent layer that surfaces the most relevant insights for their questions.
Traction and early adopters.
With pilot users at the University of Utah, we've established traction with early adopters.
We're having discussions with other universities to identify first customers. The platform is built for education, not a repurposed survey tool, but designed from the ground up for the specific rhythms and needs of higher education institutions.
Key takeaways from this project
- 0→1 product ownership: from problem definition to full-stack platform, product design, and pilot deployment.
- Full-stack product design: bringing ML-powered insights to non-technical stakeholders through thoughtful UX and data flows.
- Educator-designed: built for higher-ed rhythms, compliance, and the people who make institutions better.
- Closing the loop: connecting what students say to what leaders decide to change.